
Система мониторинга
всех медиа
Акции
Интеграция с CRM и Service Desk: как превращать упоминания в задачи
Обновлено:
Содержание
- Почему упоминания без интеграции не решают проблему
- Какие сигналы стоит превращать в задачи
- Как работает связка мониторинга с CRM или Service Desk
- Что должно попадать в карточку задачи
- Какие процессы можно автоматизировать
- Сценарии для разных команд
- Ошибки при интеграции мониторинга с CRM и Service Desk
- Как оценить эффективность такой интеграции
- Как ПрессИндекс помогает выстроить этот процесс
- Итог
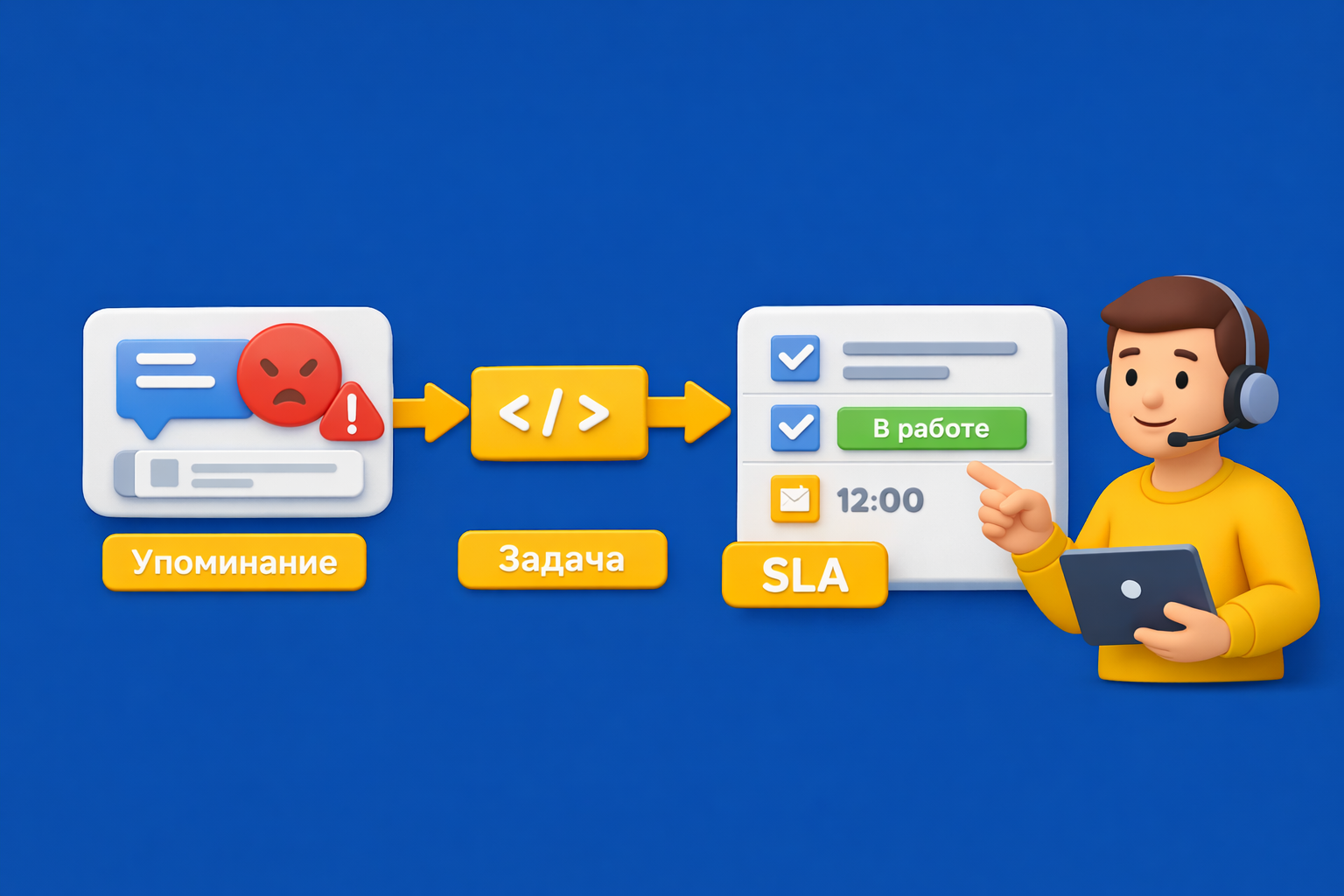
Если негатив не дошёл до нужной очереди задач, компания поздно узнаёт о сбое, пропускает запрос журналиста, не отвечает на отзыв и получает вторую волну негатива. Поэтому api интеграция и crm-интеграция нужны не ради техники, а ради управляемой реакции.
Почему упоминания без интеграции не решают проблему
Мониторинг упоминаний показывает картину поля. Но сама картина не исправляет ситуацию. Сигнал должен перейти в рабочие процессы: попасть в карточку обращения, получить приоритет, owner’а, дедлайн реакции и контроль результата.
Типовой провал выглядит просто. Система находит негативное упоминание в СМИ или Telegram, отправляет алерт на почту, дальше письмо тонет в потоке. Через несколько часов публикацию подхватывают соцсети, клиентский сервис узнаёт о жалобе из комментариев, PR подключается слишком поздно. Формально мониторинг упоминаний в интернете сработал. По факту бизнес проиграл время.
Та же логика действует для отзывов. Без связки с help desk и CRM отзыв остаётся записью в ленте. Его читают, обсуждают, откладывают, но не ведут по регламенту. Нет статуса обработки, нет контроля сроков, нет эскалации. В отчёте видно упоминание, а в операционной системе нет задачи.
Поэтому service desk интеграция закрывает разрыв между аналитикой и действием. Интеграция систем через api позволяет не просто находить сигналы, а сразу отправлять их в ту команду, которая обязана реагировать.
В чём главный смысл интеграции
Мониторинг показывает сигнал. Интеграция превращает его в задачу с владельцем, сроком, статусом и контролем результата.
Какие сигналы стоит превращать в задачи
Не каждое упоминание в сми требует тикета. В задачу переводят те сигналы, по которым нужна реакция в срок и понятен владелец процесса.
В первую очередь это негативные публикации и репутационный риск. Сюда входят критические материалы в медиа, посты в Telegram, резкие обсуждения в соцсетях, всплески негатива по бренду, продукту, топ-менеджеру или региональному офису. Для таких кейсов важны мониторинг упоминаний в сми, анализ упоминаний в сми и тональность упоминаний.
Вторая группа - мониторинг отзывов клиентов. Жалобы на геосервисах, отзовиках, маркетплейсах, в карточках компаний и соцсетях должны сразу попадать в очередь задач. Здесь важна не только репутация, но и клиентский опыт. Чем дольше отзыв висит без ответа, тем выше риск повторных обращений и публичной эскалации. Для этого процесса критичен мониторинг отзывов клиентов.
Третья группа - сигналы о сбоях и инцидентах. Сообщения о недоступности сервиса, ошибках оплаты, массовых проблемах с доставкой, отказах в обслуживании или подозрительной активности не должны ждать ручной сортировки. Такой сигнал сразу уходит в Service Desk как инцидент с высоким приоритетом.
Отдельный блок - запросы журналистов, резонансные инфоповоды и критичные сообщения от лидеров мнений. Их тоже переводят в тикеты по упоминаниям, потому что здесь важна скорость первого ответа и согласование позиции.
Как работает связка мониторинга с CRM или Service Desk
Рабочая схема интеграции выглядит так:
| Маршрут | Что это значит для бизнеса |
|---|---|
| Сигнал → фильтрация → задача → ответственный → SLA → эскалация → контроль | Упоминания и отзывы не зависают в мониторинге, а переходят в управляемый процесс с понятной зоной ответственности |
| Этап процесса | Что происходит | По каким правилам работает | Результат для команды |
|---|---|---|---|
| Сбор сигналов | Система собирает поток публикаций из СМИ, Telegram, соцсетей, геосервисов и отзовиков | Мониторинг охватывает все заданные источники и фиксирует новые упоминания в едином потоке | Команда видит не отдельные сообщения, а полную картину по бренду, продуктам и инфоповодам |
| Фильтрация | Система отбирает только значимые сигналы и убирает шум | Триггеры учитывают ключевые слова, тональность, тип площадки, регион, бренд, продукт и категорию риска | В работу попадают только события, которые требуют реакции, без перегрузки CRM и Service Desk |
| Передача в систему | Отфильтрованное упоминание уходит в CRM или help desk через webhook или API | Интеграция систем через API передаёт данные по заранее заданному сценарию | Негативный отзыв становится карточкой обращения, критичная публикация — задачей PR, сообщение о сбое — инцидентом для support |
| Назначение ответственного | Задача получает владельца сразу после создания | Маршрутизация идёт по продукту, региону, типу площадки, источнику или категории жалобы | У кейса сразу появляется owner, который отвечает за реакцию и дальнейшее движение |
| Установка SLA | Система задаёт срок первой реакции и дедлайн обработки | Для каждого типа сигнала действует свой регламент по срокам и приоритетам | Команда работает не по памяти, а по понятным срокам и правилам контроля |
| Эскалация | При нарушении срока задача автоматически поднимается выше | Правило эскалации переводит кейс тимлиду, руководителю направления или дежурной группе | Просроченные сигналы не зависают без движения и не теряются в очереди |
| Контроль статуса | Система фиксирует, что происходит с кейсом после постановки | Статусы показывают, взята ли задача в работу, обработана ли она и закрыта ли в срок | Мониторинг репутации входит в операционный контур, где каждый сигнал проходит путь от обнаружения до результата |

Что должно попадать в карточку задачи
Слабая карточка рождает лишние касания. Сотрудник открывает тикет и идёт искать контекст вручную. Это тратит время и ломает SLA.
В карточке должны быть ссылка на публикацию, текст или выдержка, источник, дата и площадка. Обязательны тональность упоминаний, тема, объект упоминания, приоритет, ответственный и срок реакции. Для сложных кейсов добавляют регион, продукт, автора сообщения, число вовлечённых пользователей и историю изменений статуса.
Хорошая карточка обращения сразу отвечает на три вопроса: что произошло, кто реагирует, до какого времени кейс должен перейти в следующий статус.
Какие процессы можно автоматизировать
Самый частый сценарий - создание тикета по отзыву. Система видит новую жалобу на геосервисе или отзовике, определяет тональность, подтягивает ссылку, текст, филиал, продукт и создаёт задачу в CRM. Ответственный получает кейс сразу, а не после ручной выгрузки. Так мониторинг отзывов перестаёт быть отдельной функцией и входит в ежедневную работу сервиса.
Второй сценарий - задача PR-команде по негативной публикации. Если поиск упоминаний в СМИ находит материал с высоким риском, система передаёт его в рабочую очередь с нужным приоритетом. В карточке уже есть источник, заголовок, цитата, дата выхода и дедлайн первой реакции. Это ускоряет согласование позиции и снижает риск второй волны.
Третий сценарий - постановка инцидента при упоминании сбоя. Мониторинг упоминаний в интернете часто первым показывает проблему: клиенты пишут о недоступности сайта раньше, чем инцидент фиксируется внутри. Если интеграция систем через api настроена правильно, такие сигналы сразу уходят в Service Desk как инциденты, а не остаются в ленте наблюдения.
Дальше подключаются эскалации. Если владелец задачи не уложился в SLA, карточка поднимается руководителю. Если негатив растёт по нескольким площадкам сразу, кейс получает новый приоритет. Если жалоба касается VIP-клиента или ключевого региона, маршрутизация меняет очередь задач без ручного переключения.
Отдельно автоматизируют распределение по брендам, продуктам, регионам и типам площадок. Один поток сигналов может обслуживать несколько команд. Тогда сервис интеграции api не просто передаёт упоминания, а раскладывает их по понятному регламенту.
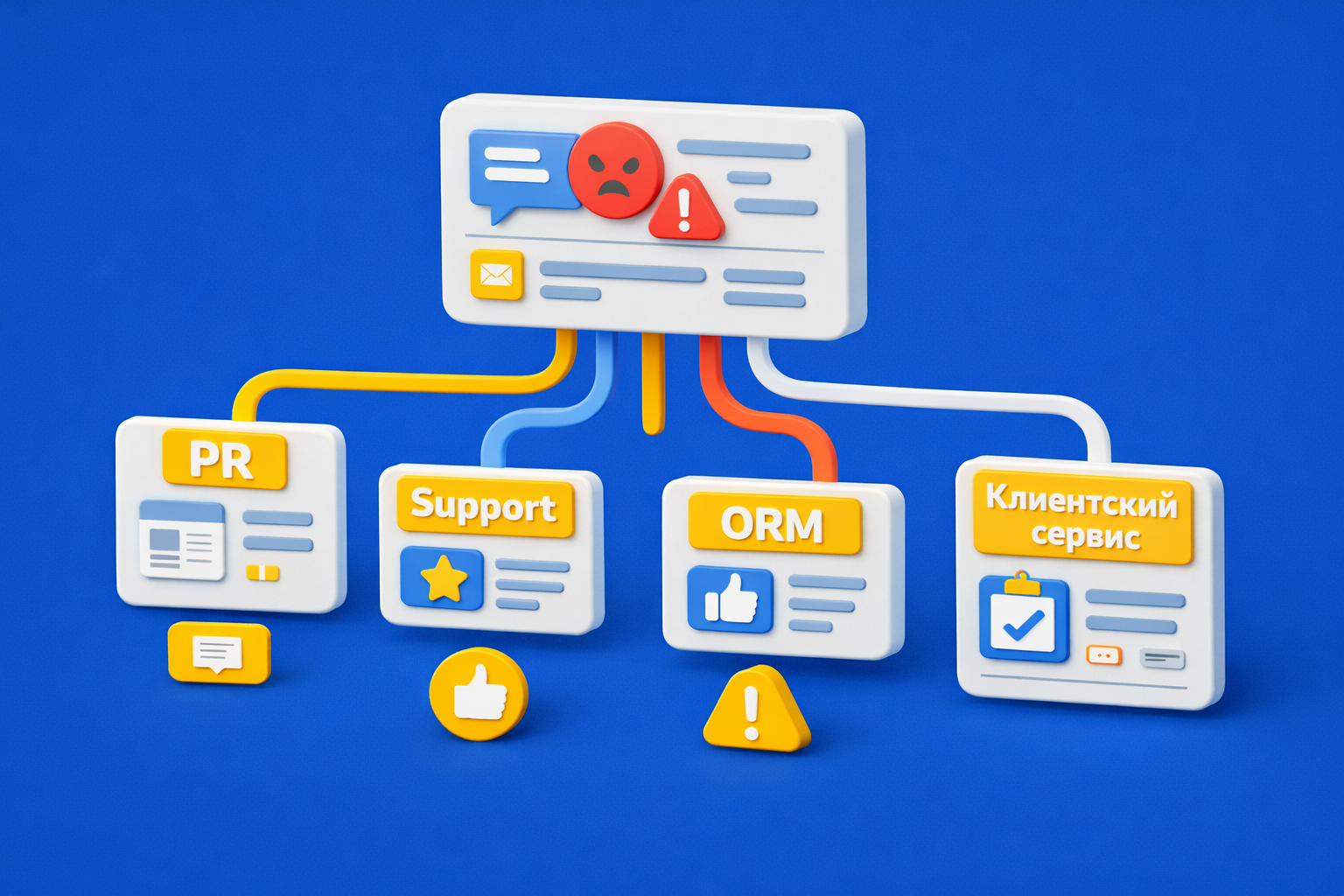
Сценарии для разных команд
PR. Получает упоминания в СМИ, Telegram и соцсетях, где есть негатив, риск резонанса, запрос журналиста или значимый инфоповод. Дальше команда готовит позицию, комментарий, опровержение или план реакции.
Клиентский сервис. Работает с жалобами, отзывами, претензиями и публичными вопросами клиентов. Здесь критичны время первой реакции, статус ответа и контроль закрытия кейса.
ORM. Берёт отзывы, рейтинги, обсуждения бренда и повторяющиеся претензии. Для ORM важны обработка упоминаний, единый стандарт ответа и контроль динамики негатива.
Support. Получает сигналы о сбоях, отказах, ошибках в продукте, падении доступа и массовых инцидентах. Здесь service desk интеграция напрямую влияет на скорость диагностики.
Risk и security. Отслеживают критичные сообщения о мошенничестве, утечках, фейках, атаках на бренд и подозрительной активности. Для этой команды важны жёсткие правила эскалации.
Маркетинг. Смотрит не только на негатив, но и на всплески интереса, инфоповоды, отзывы по новым продуктам, реакцию на запуск кампаний и сигналы для корректировки коммуникаций.
Ошибки при интеграции мониторинга с CRM и Service Desk
Первая ошибка - отправлять в CRM всё подряд. Без фильтров система создаёт шум, сотрудники перестают разбирать очередь, а важные кейсы тонут среди нейтральных упоминаний.
Вторая ошибка - не назначать owner’а. Если у задачи нет ответственного, тикет существует только формально. Такая crm-интеграция не работает как процесс.
Третья ошибка - жить без SLA. Когда нет дедлайна реакции, нельзя контролировать просрочку, сравнивать команды и разбирать узкие места.
Четвёртая ошибка - не настраивать эскалацию. Просроченная задача без escalation rule просто продолжает висеть в очереди.
Пятая ошибка - не замыкать процесс на отчётность. Если компания не видит, сколько сигналов дошло до обработки, сколько закрыто в срок и где растёт негатив, интеграция остаётся техническим проектом без эффекта для бизнеса.
Типовые ошибки
Нет фильтров, нет владельца, нет SLA, нет эскалации, нет отчётности. В такой конфигурации интеграция выглядит умной, а работает как склад хаоса.
Как оценить эффективность такой интеграции
Главный KPI - скорость реакции. Дальше смотрят долю задач в SLA, время первой реакции, число пропущенных сигналов, долю закрытых кейсов и динамику негатива после обработки.
Для больших команд важен ещё один показатель - снижение ручной нагрузки. Когда api интеграция убирает ручной разбор лент, команда тратит время не на копирование ссылок, а на решение кейсов. Это снижает операционные потери и делает контроль сроков реальным.
Полезно сравнивать каналы. Мониторинг упоминаний в СМИ, мониторинг упоминаний в социальных сетях и мониторинг отзывов дают разную скорость распространения негатива. Значит, и SLA у них должны отличаться.
Как ПрессИндекс помогает выстроить этот процесс
ПрессИндекс собирает сигналы из СМИ, соцсетей, Telegram, геосервисов и площадок с отзывами. Дальше команда настраивает правила отбора: какие упоминания в сми, отзывы, жалобы и инциденты должны попадать в работу, с каким приоритетом и в какую очередь.
Для операционного контура важны фильтры, алерты и интеграция через API. Это позволяет передавать данные во внутренние системы компании и строить подключение CRM и Service Desk без ручной пересылки ссылок и скриншотов. В результате мониторинг репутации связывается с реальными действиями команды: сигнал фиксируется, задача создаётся, SLA запускается, статус обработки контролируется.
Через мониторинг СМИ можно отслеживать публикации и медиасигналы. Через мониторинг соцсетей — видеть динамику обсуждений и реакцию аудитории. Через API-интеграцию данные передаются во внутренние контуры компании без ручной пересборки.
Итог
Итог простой. Мониторинг без интеграции показывает проблему. Интеграция с внутренними системами переводит её в рабочий процесс. Когда отзыв, жалоба, негативный пост или публикация превращаются в тикеты по упоминаниям с владельцем, сроком и эскалацией, компания реагирует быстрее, теряет меньше сигналов и лучше держит репутацию под контролем.




Обновлено:
Получите бесплатный демо-доступ на 7 дней
Подключим кабинет, покажем платформу на ваших задачах и подберём подходящие условия.
Если негатив не дошёл до нужной очереди задач, компания поздно узнаёт о сбое, пропускает запрос журналиста, не отвечает на отзыв и получает вторую волну негатива. Поэтому api интеграция и crm-интеграция нужны не ради техники, а ради управляемой реакции.
Почему упоминания без интеграции не решают проблему
Мониторинг упоминаний показывает картину поля. Но сама картина не исправляет ситуацию. Сигнал должен перейти в рабочие процессы: попасть в карточку обращения, получить приоритет, owner’а, дедлайн реакции и контроль результата.
Типовой провал выглядит просто. Система находит негативное упоминание в СМИ или Telegram, отправляет алерт на почту, дальше письмо тонет в потоке. Через несколько часов публикацию подхватывают соцсети, клиентский сервис узнаёт о жалобе из комментариев, PR подключается слишком поздно. Формально мониторинг упоминаний в интернете сработал. По факту бизнес проиграл время.
Та же логика действует для отзывов. Без связки с help desk и CRM отзыв остаётся записью в ленте. Его читают, обсуждают, откладывают, но не ведут по регламенту. Нет статуса обработки, нет контроля сроков, нет эскалации. В отчёте видно упоминание, а в операционной системе нет задачи.
Поэтому service desk интеграция закрывает разрыв между аналитикой и действием. Интеграция систем через api позволяет не просто находить сигналы, а сразу отправлять их в ту команду, которая обязана реагировать.
В чём главный смысл интеграции
Мониторинг показывает сигнал. Интеграция превращает его в задачу с владельцем, сроком, статусом и контролем результата.
Какие сигналы стоит превращать в задачи
Не каждое упоминание в сми требует тикета. В задачу переводят те сигналы, по которым нужна реакция в срок и понятен владелец процесса.
В первую очередь это негативные публикации и репутационный риск. Сюда входят критические материалы в медиа, посты в Telegram, резкие обсуждения в соцсетях, всплески негатива по бренду, продукту, топ-менеджеру или региональному офису. Для таких кейсов важны мониторинг упоминаний в сми, анализ упоминаний в сми и тональность упоминаний.
Вторая группа - мониторинг отзывов клиентов. Жалобы на геосервисах, отзовиках, маркетплейсах, в карточках компаний и соцсетях должны сразу попадать в очередь задач. Здесь важна не только репутация, но и клиентский опыт. Чем дольше отзыв висит без ответа, тем выше риск повторных обращений и публичной эскалации. Для этого процесса критичен мониторинг отзывов клиентов.
Третья группа - сигналы о сбоях и инцидентах. Сообщения о недоступности сервиса, ошибках оплаты, массовых проблемах с доставкой, отказах в обслуживании или подозрительной активности не должны ждать ручной сортировки. Такой сигнал сразу уходит в Service Desk как инцидент с высоким приоритетом.
Отдельный блок - запросы журналистов, резонансные инфоповоды и критичные сообщения от лидеров мнений. Их тоже переводят в тикеты по упоминаниям, потому что здесь важна скорость первого ответа и согласование позиции.
Как работает связка мониторинга с CRM или Service Desk
Рабочая схема интеграции выглядит так:
| Маршрут | Что это значит для бизнеса |
|---|---|
| Сигнал → фильтрация → задача → ответственный → SLA → эскалация → контроль | Упоминания и отзывы не зависают в мониторинге, а переходят в управляемый процесс с понятной зоной ответственности |
| Этап процесса | Что происходит | По каким правилам работает | Результат для команды |
|---|---|---|---|
| Сбор сигналов | Система собирает поток публикаций из СМИ, Telegram, соцсетей, геосервисов и отзовиков | Мониторинг охватывает все заданные источники и фиксирует новые упоминания в едином потоке | Команда видит не отдельные сообщения, а полную картину по бренду, продуктам и инфоповодам |
| Фильтрация | Система отбирает только значимые сигналы и убирает шум | Триггеры учитывают ключевые слова, тональность, тип площадки, регион, бренд, продукт и категорию риска | В работу попадают только события, которые требуют реакции, без перегрузки CRM и Service Desk |
| Передача в систему | Отфильтрованное упоминание уходит в CRM или help desk через webhook или API | Интеграция систем через API передаёт данные по заранее заданному сценарию | Негативный отзыв становится карточкой обращения, критичная публикация — задачей PR, сообщение о сбое — инцидентом для support |
| Назначение ответственного | Задача получает владельца сразу после создания | Маршрутизация идёт по продукту, региону, типу площадки, источнику или категории жалобы | У кейса сразу появляется owner, который отвечает за реакцию и дальнейшее движение |
| Установка SLA | Система задаёт срок первой реакции и дедлайн обработки | Для каждого типа сигнала действует свой регламент по срокам и приоритетам | Команда работает не по памяти, а по понятным срокам и правилам контроля |
| Эскалация | При нарушении срока задача автоматически поднимается выше | Правило эскалации переводит кейс тимлиду, руководителю направления или дежурной группе | Просроченные сигналы не зависают без движения и не теряются в очереди |
| Контроль статуса | Система фиксирует, что происходит с кейсом после постановки | Статусы показывают, взята ли задача в работу, обработана ли она и закрыта ли в срок | Мониторинг репутации входит в операционный контур, где каждый сигнал проходит путь от обнаружения до результата |
Что должно попадать в карточку задачи
Слабая карточка рождает лишние касания. Сотрудник открывает тикет и идёт искать контекст вручную. Это тратит время и ломает SLA.
В карточке должны быть ссылка на публикацию, текст или выдержка, источник, дата и площадка. Обязательны тональность упоминаний, тема, объект упоминания, приоритет, ответственный и срок реакции. Для сложных кейсов добавляют регион, продукт, автора сообщения, число вовлечённых пользователей и историю изменений статуса.
Хорошая карточка обращения сразу отвечает на три вопроса: что произошло, кто реагирует, до какого времени кейс должен перейти в следующий статус.
Какие процессы можно автоматизировать
Самый частый сценарий - создание тикета по отзыву. Система видит новую жалобу на геосервисе или отзовике, определяет тональность, подтягивает ссылку, текст, филиал, продукт и создаёт задачу в CRM. Ответственный получает кейс сразу, а не после ручной выгрузки. Так мониторинг отзывов перестаёт быть отдельной функцией и входит в ежедневную работу сервиса.
Второй сценарий - задача PR-команде по негативной публикации. Если поиск упоминаний в СМИ находит материал с высоким риском, система передаёт его в рабочую очередь с нужным приоритетом. В карточке уже есть источник, заголовок, цитата, дата выхода и дедлайн первой реакции. Это ускоряет согласование позиции и снижает риск второй волны.
Третий сценарий - постановка инцидента при упоминании сбоя. Мониторинг упоминаний в интернете часто первым показывает проблему: клиенты пишут о недоступности сайта раньше, чем инцидент фиксируется внутри. Если интеграция систем через api настроена правильно, такие сигналы сразу уходят в Service Desk как инциденты, а не остаются в ленте наблюдения.
Дальше подключаются эскалации. Если владелец задачи не уложился в SLA, карточка поднимается руководителю. Если негатив растёт по нескольким площадкам сразу, кейс получает новый приоритет. Если жалоба касается VIP-клиента или ключевого региона, маршрутизация меняет очередь задач без ручного переключения.
Отдельно автоматизируют распределение по брендам, продуктам, регионам и типам площадок. Один поток сигналов может обслуживать несколько команд. Тогда сервис интеграции api не просто передаёт упоминания, а раскладывает их по понятному регламенту.
Сценарии для разных команд
PR. Получает упоминания в СМИ, Telegram и соцсетях, где есть негатив, риск резонанса, запрос журналиста или значимый инфоповод. Дальше команда готовит позицию, комментарий, опровержение или план реакции.
Клиентский сервис. Работает с жалобами, отзывами, претензиями и публичными вопросами клиентов. Здесь критичны время первой реакции, статус ответа и контроль закрытия кейса.
ORM. Берёт отзывы, рейтинги, обсуждения бренда и повторяющиеся претензии. Для ORM важны обработка упоминаний, единый стандарт ответа и контроль динамики негатива.
Support. Получает сигналы о сбоях, отказах, ошибках в продукте, падении доступа и массовых инцидентах. Здесь service desk интеграция напрямую влияет на скорость диагностики.
Risk и security. Отслеживают критичные сообщения о мошенничестве, утечках, фейках, атаках на бренд и подозрительной активности. Для этой команды важны жёсткие правила эскалации.
Маркетинг. Смотрит не только на негатив, но и на всплески интереса, инфоповоды, отзывы по новым продуктам, реакцию на запуск кампаний и сигналы для корректировки коммуникаций.
Ошибки при интеграции мониторинга с CRM и Service Desk
Первая ошибка - отправлять в CRM всё подряд. Без фильтров система создаёт шум, сотрудники перестают разбирать очередь, а важные кейсы тонут среди нейтральных упоминаний.
Вторая ошибка - не назначать owner’а. Если у задачи нет ответственного, тикет существует только формально. Такая crm-интеграция не работает как процесс.
Третья ошибка - жить без SLA. Когда нет дедлайна реакции, нельзя контролировать просрочку, сравнивать команды и разбирать узкие места.
Четвёртая ошибка - не настраивать эскалацию. Просроченная задача без escalation rule просто продолжает висеть в очереди.
Пятая ошибка - не замыкать процесс на отчётность. Если компания не видит, сколько сигналов дошло до обработки, сколько закрыто в срок и где растёт негатив, интеграция остаётся техническим проектом без эффекта для бизнеса.
Типовые ошибки
Нет фильтров, нет владельца, нет SLA, нет эскалации, нет отчётности. В такой конфигурации интеграция выглядит умной, а работает как склад хаоса.
Как оценить эффективность такой интеграции
Главный KPI - скорость реакции. Дальше смотрят долю задач в SLA, время первой реакции, число пропущенных сигналов, долю закрытых кейсов и динамику негатива после обработки.
Для больших команд важен ещё один показатель - снижение ручной нагрузки. Когда api интеграция убирает ручной разбор лент, команда тратит время не на копирование ссылок, а на решение кейсов. Это снижает операционные потери и делает контроль сроков реальным.
Полезно сравнивать каналы. Мониторинг упоминаний в СМИ, мониторинг упоминаний в социальных сетях и мониторинг отзывов дают разную скорость распространения негатива. Значит, и SLA у них должны отличаться.
Как ПрессИндекс помогает выстроить этот процесс
ПрессИндекс собирает сигналы из СМИ, соцсетей, Telegram, геосервисов и площадок с отзывами. Дальше команда настраивает правила отбора: какие упоминания в сми, отзывы, жалобы и инциденты должны попадать в работу, с каким приоритетом и в какую очередь.
Для операционного контура важны фильтры, алерты и интеграция через API. Это позволяет передавать данные во внутренние системы компании и строить подключение CRM и Service Desk без ручной пересылки ссылок и скриншотов. В результате мониторинг репутации связывается с реальными действиями команды: сигнал фиксируется, задача создаётся, SLA запускается, статус обработки контролируется.
Через мониторинг СМИ можно отслеживать публикации и медиасигналы. Через мониторинг соцсетей — видеть динамику обсуждений и реакцию аудитории. Через API-интеграцию данные передаются во внутренние контуры компании без ручной пересборки.
Итог
Итог простой. Мониторинг без интеграции показывает проблему. Интеграция с внутренними системами переводит её в рабочий процесс. Когда отзыв, жалоба, негативный пост или публикация превращаются в тикеты по упоминаниям с владельцем, сроком и эскалацией, компания реагирует быстрее, теряет меньше сигналов и лучше держит репутацию под контролем.
Последние статьи
Свежие исследования, тренды и практические советы от специалистов


